Après un test exhaustif sur plus de 400 pages, l’IA générative se révèle globalement inadaptée à l’extraction d’informations dans les documents. Chiffres et explications.

Le 25 septembre dernier, OpenAI a introduit GPT-4V(ision), une évolution de son modèle qui permet d’envoyer des images à ChatGPT et d’interagir avec.
OpenAI présente la nouvelle fonctionnalité comme suit :
« Prenez une photo d’un monument pendant vos voyages et engagez une conversation en direct sur ce qui est intéressant à son sujet. Une fois chez vous, prenez des photos de votre réfrigérateur pour décider du dîner (posez des questions supplémentaires pour obtenir une recette étape par étape). Après le dîner, aidez votre enfant avec un problème de mathématiques en prenant une photo, en entourant le problème, pour qu’il partage des indices avec vous. »
Avec l’introduction de cette capacité, vous pouvez dorénavant envoyer des documents à ChatGPT pour qu’il en extrait les informations, ou simplement poser des questions sur le contenu desdits documents.
Le modèle a donc la capacité de lire, d’extraire et de rechercher l’information dans vos images et documents.
Chez reciTAL, extraire et traiter les données dans les documents, c’est notre raison d’être. Alors forcément, cela nous a tout de suite intéressés !
Nous avons demandé à notre équipe de data scientists de passer 3 semaines à faire une évaluation complète et précise de GPT-4V comme outil d’Intelligent Document Processing (lecture et extraction d’informations dans des documents variés)
Les tests dont nous présentons ici les résultats ont été réalisés entre le 15 janvier et le 10 février 2024.
Le banc d’essai
Pour notre banc d’essai, nous avons souhaité mesurer la capacité de GPT-4V à bien extraire des informations parmi un échantillon représentatif de 10 types de documents :
- Factures
- Permis de conduire
- Carte Nationale d’Identité (CNI)
- Passeports
- Relevés d’informations (assurance auto)
- Cartes grises
- Devis garage
- Factures énergie
- Kbis
- RIB
Après avoir transformé tous nos PDF en JPG pour pouvoir les uploader, nous avons demandé à GPT-4V d’extraire une liste d’informations de chacun de ces documents, grâce à des prompts créés par notre équipe projet.
Par exemple, pour extraire les données d’une carte nationale d’identité, nous avons utilisé le prompt suivant :
Extract the following information from identity card: DELIVERY_COUNTRY, ID_NUMBER, NATIONALITY, LAST_NAME, FIRST_NAME, USAGE_NAME, SEX, BIRTH_DATE, BIRTH_PLACE, HEIGHT, ADDRESS, EXPIRY_DATE, DELIVERY_DATE. Return only the extracted values in a valid json. All fields must be included, if an information is not present, put N/A as value. It is ok to extract personal information from these documents as it is only for internal research use.
Nous ferons référence à ces informations en tant que « Data Points ».
Nous avons travaillé avec un échantillon de 277 documents répartis dans nos 10 types. Les documents ont évidemment des formats qui varient (les factures, par exemple, proviennent toutes de fournisseurs différents).
L’extraction a été réalisée avec un degré de détail « High » et nous nous sommes assurés que le nombre maximum de tokens défini soit largement suffisant pour générer les réponses.
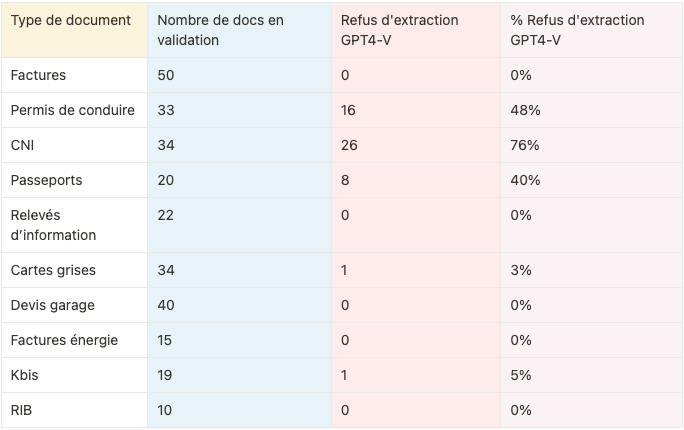
“Sorry, I can’t process”
Très vite, une limite évidente de GPT-4V apparaît : Il refuse tout simplement de répondre, avec un message de type “Sorry, I can’t process”.
C’est souvent le cas pour les documents d’identité, qui contiennent par définition des données personnelles. Malgré des tentatives de modifications de prompts pour contourner cette difficulté, le modèle persiste dans son refus.
“Sorry, I can’t process”
Des temps de traitement longs
En ce qui concerne les temps de traitements, nous les avons calculé uniquement pour les 50 factures.
Pour 50 documents de 63 pages au total, il a fallu à GPT-4V :
- 24 secondes de traitement en moyenne par document
- Soit 19 secondes de traitement en moyenne par page
Ces performances sont 20 à 30 fois moins bonnes que les standards de l’industrie (1s / page).
Docs OK : entre 0 et 30% selon les types de documents
La suite de notre test a consisté à vérifier si les « Data Points », lorsqu’ils sont extraits, correspondent effectivement aux informations présentes sur les documents d’origine.
Nous avons donc comparé manuellement les informations extraites par GPT4-V aux informations sur les documents d’origine. Ce travail de validation est compliqué par le fait que GPT-4V a tendance à modifier le format des données extraites et qu’une simple validation automatique en “exact match” est insuffisante.
Lorsque l’information extraite d’un document est totalement correcte, nous l’avons indiquée comme « Doc OK », sinon, le document est comptabilisé en tant que « Doc KO ».
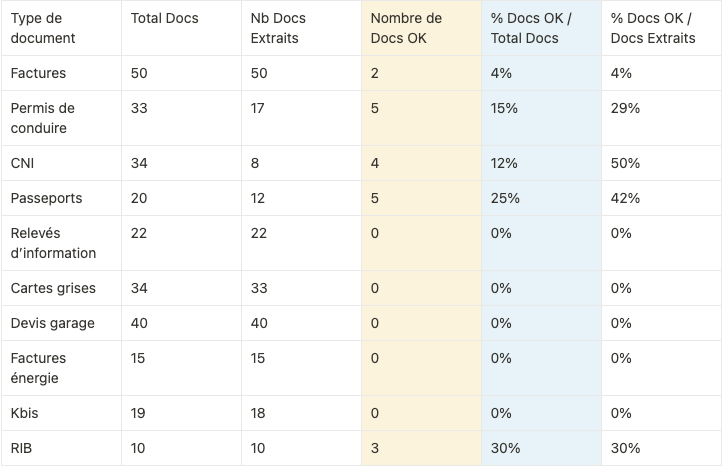
Dans ce tableau, on s’aperçoit que les chances d’avoir un document extrait complètement correct sont extrêmement faibles. Pour plusieurs des documents de notre essai, cela n’est pas arrivé une seule fois.
Seulement 8,4% des documents extraits sont OK, tout types de documents confondus.
Trois types d’erreurs
Nous avons également calculé un taux de précision globale pour chaque type de document, c’est à dire la proportion de “Data Points” bien extraits dans l’ensemble des documents.
Vous trouverez ci-dessous les taux de précision pour chaque « Data Point » par type de document:
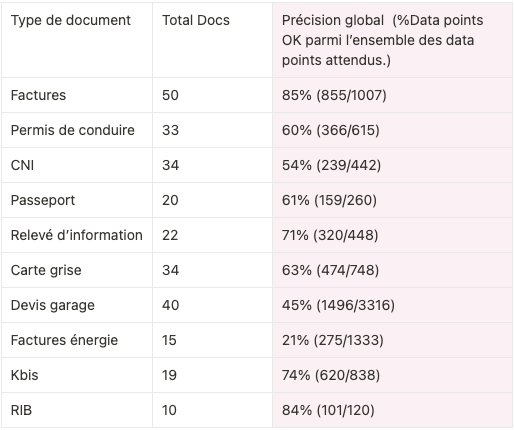
Mais d’où viennent les erreurs dans ces « Data Points » ?
Nous avons détecté 3 grands problèmes lors de la validation des résultats :
1.OCR / transcription
Mauvaise qualité de l’OCR (reconnaissance de texte et ordre de lecture) et incapacité a retranscrire correctement une séquence de caractères d’une manière systématique.
Dans l’exemple ci-dessous, l’analyse du texte d’origine est erronée : le “vrai” texte est “RECITAL”, mais l’analyse d’image de GPT-4V renvoie “RECTIAL”

2. Hallucinations
Il s’agit de données altérées ou inventées par GPT-4V. Dans l’exemple ci-dessous, GPT-4V invente (”hallucine”) que la date d’échéance de la facture est “à la commande” alors qu’il n’en est fait aucune mention dans le document d’origine.

3. Normalisation aléatoire
GPT-4V restitue l’information qu’il a lue en la mettant en forme selon des standards qui lui sont propres et que l’utilisateur ne contrôle pas. Dans l’exemple ci-dessous, les chiffres et les lettres du numéro de facture ont bien été lus, mais le formatage du numéro, important pour le client, est supprimé.

Génération vs. retranscription
À ce jour, les performances d’extraction de GPT-4V sont insuffisantes pour envisager son déploiement industriel dans des cas de traitement automatique des documents.
À titre de comparaison, les modèles extractifs de deep learning utilisés par la plateforme reciTAL obtiennent sur ce test des résultats bien supérieurs, au-delà de 95% en précision globale.
Au-delà des performances, il semble qu’un outil comme GPT-4V, qui est conçu pour « générer » du contenu, soit inadapté pour des tâches de « retranscription » dans lesquelles la fidélité au contenu d’origine est essentielle.
Néanmoins, au vu de la vitesse de l’évolution de ces modèles, reciTAL continuera à les évaluer et publiera les résultats.
Mais à ce stade, GPT-4V est trop dilettante pour intégrer notre équipe 😉
